Zero-like reinforcement learning model, Monte Carlo Tree Search for hexapawn chess, similar to the DeepMind’s AlphaZero approach. And visualisation of tree search.
Practical walktrough to understand the basics of the zero-like reinforcment learning method and Monte Carlo Tree Search (MCTS). Which is possible then was transfered to real industrial NP-hard combinatorial optimization problem - finding the best topologies for industrial network devices.
Self play with reinforcement learning
High-level training loop of the zero-like reinforcement learning pipeline.
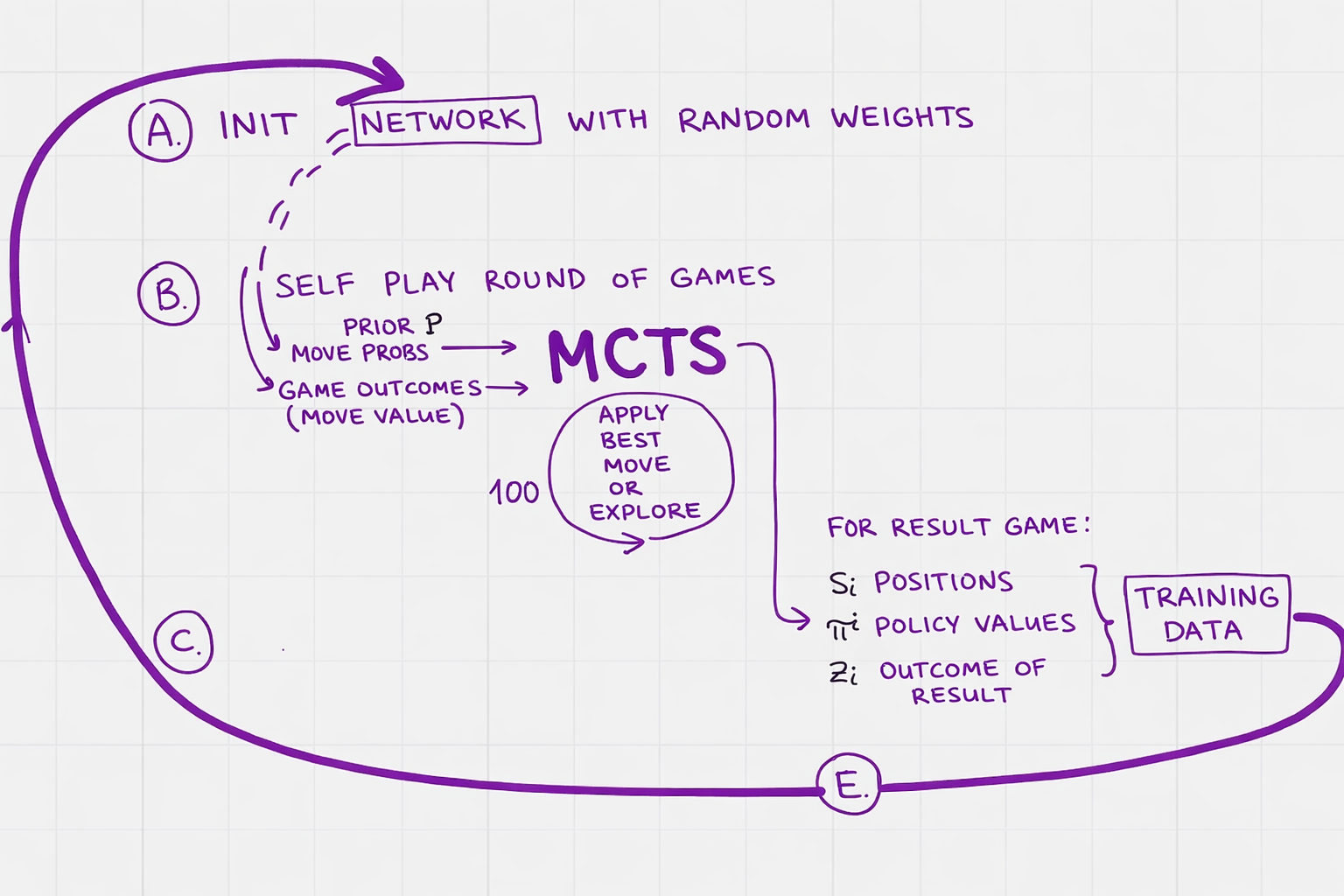
Training without input data: in zero-sum self-play game two players play against each other for a bit. The game results compared with the model’s predictions, the network is updated, then self-play again with the updated predictions, then network updated, then self-play, … self-learning…
Here is full implementation of the method for small chess game Hexapawn, thank you Dominik Klein and his book “Neural Networks for Chess”.